Blog

Zwischen Effizienz und Entfremdung: KI im Entwickleralltag
- Details
- Kategorie: Maschinelles Lernen
Als Softwareentwickler schreibe ich ab und zu einen Blog-Beitrag. Nicht regelmässig, nicht strategisch geplant, sondern wenn mich ein Thema beschäftigt. Und genau so ein Thema hat sich in den letzten Monaten bei mir festgesetzt: die Nutzung von Large Language Models und Diffusion-Models beim Schreiben und Entwickeln. Ich nutze sie. Regelmässig. Für Blog-Beiträge, für Beitragbilder, für Code. Doch je mehr ich sie einsetze, desto unbehaglicher wird mir bei gewissen Aufgaben. Es ist, als würde ich langsam vom Schöpfer meiner Arbeit zum Konsumenten degradiert – und das ist ein seltsames, unangenehmes Gefühl.
Diese Zeilen hier? Sie sind ein Versuch, dieses Unbehagen zu verstehen. Eine Auseinandersetzung mit der Frage, wann KI hilfreich ist und wann sie schadet. Wann sie mich unterstützt und wann sie mich ersetzt. Und vor allem: Wann ich aufhören sollte, sie zu nutzen, weil ich sonst Gefahr laufe, meine eigenen Fähigkeiten und mein tiefes Verständnis für meine Arbeit zu verlieren.
KI als willkommener Helfer – für manche Aufgaben
Beitragbilder und kreative Schwächen
Es gibt Bereiche, in denen mir KI das Leben massiv erleichtert. Beitragbilder sind so ein Bereich. Ich habe durchaus eine Vorstellung davon, wie ein Bild zu meinem Blog-Beitrag aussehen könnte. Ich sehe es vor mir: die Farben, die Stimmung, die Komposition. Aber zwischen dieser Vision und der technischen Umsetzung liegt ein Graben, den ich nicht ohne weiteres überbrücken kann. Ich habe zwar Grundkenntnisse von Grafikprogrammen und kenne auch gewisse Design-Prinzipien, trotzdem müsste ich viele Stunden investieren – und am Ende würde vermutlich trotzdem etwas Mittelmässiges herauskommen, weil mir das tiefergehende gestalterische Talent fehlt.
Früher hätte ich diese Aufgabe an jemand Fähigeren delegieren müssen, an einen Designer, der meine vage Vorstellung in etwas Konkretes verwandelt. Heute tippe ich meine Vorstellung in ein Diffusion-Model und bekomme in Sekunden mehrere Varianten. Ist das Ergebnis perfekt? Selten. Aber es ist gut genug, und vor allem: Der Aufwand steht in keinem Verhältnis zum Nutzen. Hier ist die KI für mich ein echter Gewinn, weil sie eine Lücke füllt, die ich selbst nicht schliessen kann oder will.
Deep Research und strukturierte Analysen
Ähnlich verhält es sich mit Rechercheaufgaben. Google Deep Research finde ich beispielsweise praktisch für die Analyse eines Unternehmens. Die KI durchforstet Quellen, strukturiert Informationen, fasst zusammen. Natürlich muss ich die Ergebnisse kritisch prüfen, aber der erste, mühsame Schritt – das Zusammentragen von Fakten – ist deutlich schneller erledigt. Bei solchen faktenbasierten Aufgaben, die repetitiv sind und bei denen es um das Sammeln und Strukturieren von Informationen geht, fühlt sich der KI-Einsatz richtig an. Ich spare Zeit, ohne dass mir etwas verloren geht.
Die Grauzone: Blog-Beiträge und das Konsumenten-Gefühl
Der Unterschied zwischen Schreiben und Schreiben-Lassen
Doch dann gibt es die Grauzone. Blog-Beiträge zum Beispiel. Ich nutze LLMs, um mich beim Schreiben zu unterstützen. Manchmal lasse ich mir Abschnitte generieren, die ich dann überarbeite. Manchmal nutze ich die KI, um meine Gedanken zu strukturieren oder Formulierungen zu verbessern. Das klingt effizient, und manchmal ist es das auch. Aber es fühlt sich anders an als ein Text, den ich von A bis Z selbst geschrieben habe.
Bei Blog-Beiträgen, in denen ich nicht mit jedem einzelnen Satz gerungen habe, bekomme ich das Gefühl, dass ich nicht der Creator bin, sondern der Konsument. Als hätte nicht ich den Text geschrieben, sondern jemand anders für mich. Ich habe ihn gelesen, vielleicht angepasst, aber nicht wirklich erschaffen. Das ist ein subtiler, aber wichtiger Unterschied. Die tiefe Auseinandersetzung mit jedem Gedanken, das Ringen um die richtige Formulierung, das Verwerfen und Neuanfangen – all das fällt weg. Und mit ihm offenbar auch ein Teil des Lernprozesses.
Was die Hirnforschung dazu sagt
Dass dieses Gefühl nicht nur subjektiv ist, zeigt eine faszinierende Studie des MIT Medialabs. Nataliya Kosmyna und ihr Team haben untersucht, was im Gehirn passiert, wenn Menschen Essays mit ChatGPT schreiben. Das Ergebnis: Die ChatGPT-Gruppe zeigte eine auffällig geringere "Gehirnkonnektivität" – also weniger Austausch zwischen verschiedenen Hirnregionen. Noch bemerkenswerter: Die Teilnehmenden konnten sich 60 Sekunden später kaum noch an die Inhalte ihrer eigenen Texte erinnern.
Sie hatten die Essays gelesen, aber nicht wirklich verarbeitet. Die Informationen waren nie tief genug ins Gehirn vorgedrungen. Im Vergleich dazu aktivierte die Gruppe, die mit Suchmaschinen arbeitete, vermehrt das visuelle Zentrum und zeigte insgesamt deutlich mehr Hirnaktivität. Sie mussten aktiv Informationen zusammensuchen, zwischen Tabs wechseln, Inhalte verarbeiten. Bei der ChatGPT-Gruppe fehlte genau dieser Schritt – die Information wurde fertig serviert.
Die Forschung spricht von "cognitive offloading" – wir lagern kognitive Aufgaben aus. Unser Gehirn ist faul und nimmt gerne Abkürzungen. Das ist evolutionär sinnvoll: Warum Energie verschwenden, wenn es auch einfacher geht? Doch die Evolution hat möglicherweise nicht vorhergesehen, dass wir uns smarte Helfer bauen, die uns quasi alle kognitiven Aufgaben abnehmen können. Und genau das führt langfristig dazu, dass wir tatsächlich Fähigkeiten verlernen – zum Beispiel das Lernen selbst.
Software-Entwicklung: Wo KI hilft und wo sie stört
Die hilfreichen Bereiche
In der Software-Entwicklung zeigt sich diese Ambivalenz besonders deutlich. Es gibt Bereiche, in denen mir die KI sehr gelegen kommt. HTML-Kenntnisse beispielsweise: Mir sind die Möglichkeiten von HTML nicht immer bewusst. Welche Attribute gibt es? Wie kann ich bestimmte Effekte erreichen? Ich könnte das nachschlagen, aber ehrlich gesagt fasziniert mich dieser Teil der Entwicklung nicht besonders. Ich will es einfach gelöst haben. Die KI kennt die Spezifikationen, schlägt Lösungen vor, und ich kann weitermachen.
Auch beim extensiven Kommentieren hilft die KI. Nicht nur, weil mein Englisch nicht perfekt ist, sondern auch, weil sie ausführlicher und strukturierter dokumentiert, als ich es tun würde. Testcode lasse ich mir ebenfalls oft generieren. Warum auch nicht? Es ist repetitiv, folgt klaren Mustern, und die KI macht das zuverlässig.
All diese Aufgaben haben etwas gemeinsam: Sie liegen ausserhalb meiner Kernkompetenz oder interessieren mich schlicht nicht besonders. Es sind Tätigkeiten, die erledigt werden müssen, aber nicht das Herzstück meiner Arbeit darstellen. Hier empfinde ich die KI als legitimes Werkzeug.
Die kritischen Bereiche: Der Kern der Applikation
Qualitätsanforderungen und implizites Wissen
Doch dann gibt es den Kern der Applikation. Jenen Bereich, in dem ich glaube, meine Stärke zu haben. Hier werde ich skeptisch. Erstens habe ich bestimmte Qualitätsanforderungen. Die Architektur soll elegant sein, der Code wartbar, die Abstraktion auf dem richtigen Level. Das sind Dinge, die ein LLM schwer beurteilen kann, weil sie Erfahrung, Kontext und langfristiges Denken erfordern.
Zweitens – und das ist vielleicht noch wichtiger – habe ich sehr viel implizites Wissen über meinen eigenen Code. Er wurde ja selbst erarbeitet. Ich weiss, warum ich bestimmte Entscheidungen getroffen habe. Ich kenne die Stellen, an denen die Abstraktion bewusst noch nicht perfekt ist, weil noch nicht klar war, wie sich die Anforderungen entwickeln. Ich erkenne sofort, wenn eine neue Funktionalität die Chance bietet, bestehenden Code zu generalisieren.
Die Gefahr der Code-Aufblähung
Ein LLM hat dieses Wissen nicht. Es sieht meinen Code, aber es versteht nicht die Geschichte dahinter, die Überlegungen, die Absichten. Ich befürchte, dass ein LLM dies zu wenig berücksichtigt und den Sourcecode aufbläht. Statt eine elegante Generalisierung zu finden, die zwei ähnliche Funktionen zusammenführt, fügt es einfach eine weitere ähnliche Funktion hinzu. Der Code wird länger, redundanter, schwerer wartbar.
Das ist meine grösste Sorge: Ich möchte nicht zum Konsumenten meiner eigenen Codebasis werden. Ich möchte nicht eines Tages vor meinem eigenen Projekt stehen und nicht mehr genau verstehen, warum etwas so implementiert ist, wie es implementiert ist. Ich möchte nicht den Überblick verlieren über die Architektur, die Muster, die Entscheidungen. Denn dann habe ich die Kontrolle verloren.
Vom Schöpfer zum Konsumenten der eigenen Codebasis
Genau das ist das Gefühl, das mich beschleicht, wenn ich zu viel KI-generierten Code übernehme: Ich werde zum Konsumenten. Ich lese den Code, ich verstehe ihn oberflächlich, aber ich habe ihn nicht durchdacht. Die tiefe Auseinandersetzung, die beim manuellen Schreiben stattfindet – das Überlegen, Verwerfen, Neuansetzen –, fehlt. Und mit ihr fehlt auch das tiefe Verständnis.
Katharina Scheiter, Professorin für Lehr-Lernforschung an der Uni Potsdam, warnt genau davor: Wenn wir Inhalte nicht mehr selbst prozessieren, lernen wir dabei auch nichts. Wir verlieren die Fähigkeit, uns komplexen Inhalten zuzuwenden, bei denen wir uns anstrengen müssen. Und diese Anstrengung ist genau das, was echtes Lernen ausmacht.
Der Flow beim Programmieren
Wahrscheinlich beobachten nicht nur ich bei sich einen bestimmten Rhythmus beim Programmieren. Man schreibt ein einfaches Stück Sourcecode, während das Gehirn teilweise schon viel weiter denkt. Man hat das Gefühl, die Hände beherrschen das 10-Finger-System beim Schreiben und es verursacht keine mentale Anstrengung. Ähnlich verhält es sich beim Programmieren: Die Finger schreiben, ein Teil des Gehirns verfasst nebenläufig den aktuellen Teil des Codes, während es zur selben Zeit schon viel weiter denkt. An der nächsten Funktion, an der Schnittstelle, an möglichen Edge Cases.
Dieser Rhythmus, dieser Flow, ändert sich durch das Prompting grundsätzlich. Statt in diesem kontinuierlichen Denkstrom zu bleiben, muss ich pausieren, meine Anforderung formulieren, warten, das Ergebnis prüfen, anpassen. Der Fluss wird unterbrochen. Es ist auch ein Grund, warum ich kein Freund des Pair Programming bin, da auch dieses verhindert, dass ich den Flow erreiche. Das ständige Erklären, Diskutieren, Abstimmen reisst mich aus diesem produktiven Zustand heraus. Alleine bin ich in dieser Angelegenheit am besten.
Das klingt vielleicht egozentrisch, aber es geht um etwas Wichtiges: In diesem Flow-Zustand entstehen die besten Lösungen. Hier sehe ich Zusammenhänge, die mir sonst entgehen würden. Hier entwickle ich elegante Abstraktionen. Und genau diesen Zustand gefährde ich, wenn ich zu früh auf KI-Unterstützung setze.
Warum Programmieren fasziniert
Einer der Hauptgründe, warum ich Softwareentwickler bin, ist, dass man ein ziemlich genaues Ziel ansteuert. Der Weg dorthin ist nicht exakt vorbestimmt, sondern kann sich ändern, während man sich damit beschäftigt. Grössere Ziele werden in Etappen gelöst. Das Bewältigen einer solchen Etappe beschert einem ein kleines Erfolgserlebnis. Manchmal fühlt es sich so an, als würde alles gelingen, und manchmal beisst man sich dabei fast die Zähne aus. Letztendlich ziehe ich wahrscheinlich daraus meine Motivation, auch weil die Problemlösungen manchmal wirklich elegant sind. Sicherlich würde man mit besserem Wissen einige Male eine viel bessere Lösung finden.
Beim Prompting fehlen genau diese kleinen Schritte, die solche Erfolgserlebnisse bescheren. Die KI liefert die Lösung auf einmal, komplett, fertig. Man überspringt all die kleinen Siege auf dem Weg dorthin. Das mag effizient erscheinen, aber es nimmt einem etwas Wesentliches: die Befriedigung, etwas selbst herausgefunden zu haben. Die Freude am Prozess, nicht nur am Ergebnis. Und vielleicht ist genau das der Kern des Problems: KI optimiert für das Ergebnis, aber Lernen und Wachstum finden im Prozess statt.
Der entscheidende Faktor: Zeitpunkt und Reihenfolge
Erst denken, dann KI nutzen
Interessanterweise gibt es eine zweite, kleinere Testreihe in der MIT-Studie, die oft übersehen wird. Die Forschenden vertauschten einige Monate nach der ersten Runde die Gruppen: Wer zuvor ohne KI gearbeitet hatte, durfte nun ChatGPT nutzen, und umgekehrt. Das Ergebnis war verblüffend. Wer zuerst selbst denken musste und dann die KI nutzte, wies nicht nur eine höhere Gehirnkonnektivität auf, sondern produzierte auch durchdachtere Aufsätze. Diese Gruppe nutzte ChatGPT völlig anders: Sie stellten Fragen, diskutierten ihre Thesen, suchten nach Gegenargumenten. Sie setzten sich mit ihren eigenen Gedanken auseinander, statt sich den Aufsatz schreiben zu lassen.
Das deutet darauf hin, dass der Zeitpunkt entscheidend sein könnte. Erst selbst denken, dann die KI nutzen – das scheint die produktivste Kombination zu sein. Diejenigen, die plötzlich ohne ChatGPT arbeiten mussten, zeigten dagegen eine deutlich verringerte Konnektivität. Sie hatten sich daran gewöhnt, dass das Denken abgenommen wird.
KI als Lektor, nicht als Autor
Ethan Mollick, Professor an der University of Pennsylvania, formuliert es so: Das Problem ist nicht das Schummeln bei den Hausaufgaben. Das Problem ist, dass selbst ehrliche Versuche, KI als Hilfe zu nutzen, nach hinten losgehen können, da der Standardmodus der KI darin besteht, die Arbeit für uns zu erledigen, nicht mit uns. Er selbst hat sich eine Regel auferlegt: Für jeden Text zwingt er sich, erst selbst einen kompletten Entwurf anzufertigen – bis auf die Recherche ganz ohne KI. Das sei mühsam, gibt er zu. Erst danach nutzt er Chatbots als Lektoren: Was ist unklar? Wie könnte der Text verständlicher werden? Die KI als kritischer Leser, nicht als Ghostwriter. Diese Disziplin erscheint mir zunehmend wichtig. Nicht "KI, schreib mir einen Artikel über X", sondern: Ich schreibe den Artikel, und die KI hilft mir, ihn zu verbessern. Der entscheidende kognitive Prozess – das Durchdenken, Strukturieren, Formulieren – findet bei mir statt, nicht bei der Maschine.
Bildung und Informatik: Was Kinder wirklich brauchen
Die fragwürdige Forderung nach Programmierunterricht
Diese Überlegungen führen mich zu einer weiteren Frage: Was bedeutet das für die Bildung? Es gibt eine verbreitete Forderung, dass Kinder programmieren lernen sollten. Alle sollten coden können, heisst es. Informatik ab der Grundschule.
Ich war noch nie ein Freund dieser Idee, dass Kinder in der Schule obligatorisch Programmieren lernen sollten. Seit 2010, mit der Einführung des Raspberry Pi, gibt es günstige Computer, mit denen sich ambitionierte Kinder das Programmieren selbst beibringen können. Seit dieser Zeit gibt es auch genügend Online-Lernmaterialien in hervorragender Qualität, oft sogar kostenlos. YouTube-Tutorials, interaktive Plattformen, ganze Kurse. Wer programmieren lernen will, kann das heute problemlos tun. Die Hürden sind so niedrig wie nie zuvor.
Ein prominentes Beispiel für die entgegengesetzte Haltung lieferte Philip Hildebrand, damals Vizepräsident von BlackRock, am Swiss Economic Forum 2016. In seiner Rede formulierte er eine klare Forderung:
Quelle: SRF 09.06.2016 - SEF: Philipp Hildebrand fordert Offensive in der Bildung
Diese Analogie zum Lesen und Schreiben klingt zunächst überzeugend. Doch bei genauerem Hinsehen hinkt der Vergleich erheblich. Ich möchte mehrere Gründe nennen, weshalb Programmieren eben nicht in den obligatorischen Lehrplan gehört.
Warum die Analogie zum Lesen und Schreiben nicht funktioniert
Erstens: Lesen und Schreiben sind universelle Kulturtechniken, Programmieren nicht. Jeder Mensch muss in unserer Gesellschaft lesen und schreiben können, um am täglichen Leben teilzunehmen. Ohne diese Fähigkeiten ist man ausgeschlossen. Programmieren hingegen ist eine Spezialdisziplin. Die allermeisten Menschen kommen ihr ganzes Leben lang gut ohne aus.
Zweitens: Intrinsische Motivation fehlt bei den meisten. Programmieren ist wahrscheinlich für die meisten Kinder und Jugendliche sehr langweilig. Syntax lernen, Schleifen verstehen, Bedingungen formulieren: das ist abstrakt und trocken. Anders als beim Lesen und Schreiben, wo Kinder schnell den Nutzen sehen (Geschichten lesen, Nachrichten schreiben, Schilder verstehen), ist der Mehrwert beim Programmieren für die meisten nicht erkennbar.
Möglicherweise ist es interessanter, wenn reale Objekte mit Softwarecode gesteuert werden, wenn Kinder einen Roboter bauen und programmieren können. Aber auch das wird nur einen kleinen Teil der Kinder wirklich faszinieren. Und genau hier liegt der Kern: Ich bin der Meinung, Kinder sollten sich für ein Thema interessieren, dann lernen sie es auch. Wo das Interesse fehlt, ist es verschwendete Zeit.
Ich habe als Kind niemanden gebraucht, der mir sagt, dass ich programmieren lernen soll. Ich wollte es, also habe ich es gemacht. Und heute ist es noch einfacher: Ein Raspberry Pi kostet weniger als 50 Franken, eine stabile Internetverbindung vorausgesetzt hat man Zugang zu unbegrenzten Lernressourcen. Was vielleicht noch mehr fasziniert, ist die Anwendung eines Arduino Uno, weil dieser noch einfacher mit Elektronik verbunden werden kann. Etwas mit Sensoren und Aktoren zu bauen, eine LED zum Leuchten zu bringen, einen Motor zu steuern oder Temperatur zu messen, das könnte für viele Kinder deutlich spannender sein als abstrakte Syntax auf einem Bildschirm. Hier wird Programmierung greifbar, sichtbar, erlebbar. Aber auch das funktioniert nur, wenn das Interesse da ist. Wer programmieren lernen will, kann das tun. Wer nicht will, sollte nicht gezwungen werden.
Drittens: Die Welt hat sich seit 2016 verändert. Hildebrands Tochter konnte Apps benutzen, aber nicht "schreiben", also nicht programmieren. Seine Forderung war: Das müssen wir ändern. Doch heute, 2025, stellt sich die Frage ganz anders: Müssen Kinder wirklich programmieren lernen, wenn sie mit natürlicher Sprache KI-Systeme anweisen können, Programme zu schreiben? Die Fähigkeit, der KI gute Anweisungen zu geben, unterscheidet sich fundamental vom Schreiben von Code.
Wirtschaftliche Interessen versus Bildungsauftrag
Die Anforderung, dass alle Kinder programmieren lernen sollten, ist meiner Meinung nach stark von wirtschaftlichen Interessen geprägt. Die Wirtschaft braucht Programmierer, also sollen die Schulen sie ausbilden. Hildebrand sprach ja explizit im Kontext der wirtschaftlichen Herausforderungen der digitalen Transformation. Das ist nachvollziehbar aus Unternehmenssicht, aber ist es der richtige Bildungsauftrag?
Die Schule sollte nicht primär Arbeitskräfte für die Wirtschaft produzieren, sondern junge Menschen befähigen, kritisch zu denken, sich selbständig Wissen anzueignen und ein erfülltes Leben zu führen. Programmieren kann dazu beitragen, aber nur für jene, die sich dafür interessieren.
Was Kinder wirklich lernen sollten
Dabei gibt es durchaus sinnvolle Ansätze: Computational Thinking, also das Denken in Algorithmen und Strukturen, kann hilfreich sein. Probleme in Teilprobleme zerlegen, Muster erkennen, abstrakt denken: das sind übertragbare Fähigkeiten. Aber dafür muss man nicht zwingend in Python oder JavaScript programmieren. Das kann man auch ohne Code lernen.
Was Kinder heute wirklich brauchen, ist etwas anderes:
Sie müssen lernen, kritisch zu denken. Gerade im Zeitalter der KI ist es wichtiger denn je, Ergebnisse bewerten zu können. Ist diese Information korrekt? Ist dieser Code sinnvoll strukturiert? Sind diese Argumente stichhaltig?
Sie müssen verstehen, was Algorithmen grundsätzlich tun, auch wenn sie sie nicht selbst schreiben. Wie funktioniert eine Suchmaschine? Was ist ein Algorithmus? Wie treffen KI-Systeme Entscheidungen? Dieses konzeptuelle Verständnis ist wichtiger als die Fähigkeit, eine for-Schleife in Java zu schreiben.
Sie müssen lernen, wann sie der KI vertrauen können und wann nicht. Wann sie selbst denken müssen und wann die KI hilfreich ist. Diese metakognitive Fähigkeit ist fundamental und schliesst sich hier an meine früheren Überlegungen an.
Prompting ist nicht Programmieren, und das ist der entscheidende Punkt
Hildebrands Analogie von 2016 lautete: Kinder können "lesen" (Apps benutzen), aber nicht "schreiben" (programmieren). Heute müssen wir die Analogie anders formulieren: Kinder können "lesen" (Technologie nutzen) und sie können auch "schreiben", nur eben nicht in Programmiersprachen, sondern in natürlicher Sprache, die KI-Systeme verstehen.
Prompting ist nicht Programmieren. Die Fähigkeit, einer KI gute Anweisungen zu geben, einem System präzise Anforderungen zu kommunizieren, Ergebnisse kritisch zu bewerten: das sind die relevanten Fähigkeiten. Und die unterscheiden sich fundamental vom klassischen Programmieren.
Wenn wir davon ausgehen, dass KI-Systeme künftig einen grossen Teil der tatsächlichen Programmierung übernehmen, dann ist die Frage nicht: "Können unsere Kinder Code schreiben?", sondern: "Können unsere Kinder denken? Können sie Probleme analysieren? Können sie beurteilen, ob eine Lösung gut ist?"
Die Gefahr des erzwungenen Lernens
Und genau deshalb ist die obligatorische Programmierung im Lehrplan problematisch. Erinnern wir uns an die Erkenntnisse aus der Hirnforschung: Lernen funktioniert am besten, wenn wir uns anstrengen müssen, aber aus eigenem Antrieb. Die Dopaminausschüttung, die fürs Lernen nötig ist, entsteht durch Anstrengung, die sich lohnt. Durch Herausforderungen, denen wir uns freiwillig stellen.
Erzwungenes Lernen in einem Bereich, der die meisten Kinder nicht interessiert, führt zu genau dem, was wir bei der unreflektierten ChatGPT-Nutzung gesehen haben: oberflächliches Verarbeiten, schnelles Vergessen, kein tiefes Verständnis. Die Kinder lernen vielleicht, eine for-Schleife zu schreiben, aber sie verstehen nicht wirklich, was sie tun. Und nach der Prüfung ist das Wissen wieder weg.
Die bessere Alternative
Statt Programmieren obligatorisch zu machen, sollten wir:
Interesse wecken, nicht erzwingen. Angebote schaffen für jene, die sich dafür begeistern. Programmier-AGs, Robotik-Clubs, Hackathons. Wer Interesse hat, wird kommen. Wer keines hat, soll seine Energie in Bereiche stecken können, die ihn faszinieren.
Konzeptuelles Verständnis vermitteln. Alle sollten verstehen, wie digitale Systeme grundsätzlich funktionieren. Was ist ein Algorithmus? Wie lernt eine KI? Was sind Daten? Das braucht keinen Code, sondern gute Erklärungen und praktische Beispiele.
Kritisches Denken fördern. Die Fähigkeit, Informationen zu bewerten, Argumente zu prüfen, Fehler zu erkennen: das ist universell wichtig. Gerade im Zeitalter der KI.
Metakognition trainieren. Wann brauche ich Hilfe? Wann verstehe ich etwas nicht wirklich? Wann täusche ich mir Verständnis vor? Diese Reflexionsfähigkeit ist zentral, und sie hilft nicht nur in der Informatik.
Herr Hildebrand, Sie fragten nach einem Grund, weshalb Programmieren nicht in den obligatorischen Lehrplan gehört. Hier sind mehrere: Weil die meisten Kinder kein Interesse daran haben. Weil erzwungenes Lernen ineffektiv ist. Weil die Fähigkeiten, die heute zählen, andere sind. Und weil Ihre Töchter längst "schreiben" können, nur eben nicht in Python, sondern in natürlicher Sprache, die mächtigere Werkzeuge versteht.
Die Schule soll nicht Programmierer ausbilden. Sie soll denkende, kritische, neugierige Menschen hervorbringen. Manche davon werden Programmierer. Die meisten nicht. Und das ist völlig in Ordnung.
Fazit: Die Stellschraube richtig einstellen
Persönliche Leitlinien für den KI-Einsatz
Zurück zu meiner Ausgangsfrage: Wann hilft KI, wann schadet sie? Nach all diesen Überlegungen kristallisieren sich für mich einige Leitlinien heraus:
Für Aufgaben ausserhalb meiner Kernkompetenz ist KI ein Segen. Beitragbilder, Übersetzungen, Recherche – hier nutze ich sie ohne schlechtes Gewissen. Sie füllt Lücken, die ich selbst nicht oder nur mit unverhältnismässigem Aufwand schliessen könnte.
Erweitern von eigenen Fähigkeiten: Ein besonders wertvoller Einsatzbereich. Manchmal habe ich Grundkenntnisse über ein bestimmtes Thema, möchte aber tiefer einsteigen. Hier ist ein Dialog mit einem Chatbot extrem hilfreich. Ich kann Fragen stellen, Verständnisfragen nachschieben, um Beispiele bitten, Zusammenhänge erklärt bekommen. Dieser iterative Prozess, bei dem ich aktiv Fragen formuliere und die Antworten hinterfrage, finde ich deutlich erfolgreicher als die traditionelle Methode über Google Search und die angebotenen Links. Bei der Google-Suche muss ich durch verschiedene Websites navigieren, unterschiedliche Schreibstile und Qualitätsniveaus verarbeiten, selbst die Puzzleteile zusammensetzen. Der Chatbot hingegen passt sich meinem Wissensniveau an und baut darauf auf. Entscheidend ist aber: Ich stelle die Fragen, ich denke mit, ich hinterfrage. Die KI ist hier ein geduldiger Tutor, kein Ersatz fürs eigene Denken.
Bei meiner Kernarbeit – der Software-Entwicklung, dem Schreiben – bin ich vorsichtiger geworden. Hier gilt: Erst selbst denken, dann KI als Unterstützung. Nie als Ersatz. Der kognitive Prozess muss bei mir stattfinden, nicht bei der Maschine. Die KI kann polieren, verbessern, hinterfragen – aber nicht erschaffen.
Am kritischsten bin ich beim Kern meiner Applikationen. Hier geht es nicht nur um Code, sondern um Architektur, um langfristige Entscheidungen, um implizites Wissen. Hier möchte ich nicht zum Konsumenten werden. Hier ist die Gefahr am grössten, dass ich die Kontrolle und das tiefe Verständnis verliere.
Die Balance finden
Ob KI uns "dümmer" oder "schlauer" macht, hängt also weniger von der Technik als von uns selbst ab. Wir haben eine Stellschraube in der Hand, wie Katharina Scheiter es formuliert. Wenn wir sie falsch stellen, haben wir ein Problem.
Die Gefahr ist real, dass sich eine digitale Kluft entwickelt: zwischen denen, die KI so einsetzen, dass sie Dinge tatsächlich tief durchdringen, und jenen, die Aufgaben mit KI lösen, ohne zu merken, dass sie wichtige Dinge nicht nachhaltig verstanden haben. Die einen nutzen KI als Verstärker ihrer Fähigkeiten, die anderen als Ersatz.
Ich will zur ersten Gruppe gehören. Das bedeutet Disziplin. Es bedeutet, manchmal den mühsameren Weg zu gehen. Es bedeutet, der Versuchung zu widerstehen, einfach "ChatGPT, mach das für mich" zu tippen. Es bedeutet, bewusst zu entscheiden, wann ich die KI nutze und wann nicht.
Ausblick
Das ist anstrengend, keine Frage. Die Hirnforschung zeigt immer wieder, dass echtes Lernen Anstrengung erfordert. Die für Motivation und Lernen nötige Dopaminausschüttung findet nur statt, wenn wir uns vorher angestrengt haben. Lernen ist am effektivsten, wenn wir aus der Komfortzone müssen – nicht, wenn es uns leichtfällt.
Die KI macht es uns leicht. Zu leicht, vielleicht. Sie nimmt uns die Anstrengung ab, und damit auch den Lerneffekt. Wer sich dauerhaft die Hausaufgaben machen lässt, verpasst nicht nur den Stoff, sondern verlernt auch, wie man lernt.
Gleichzeitig will ich die KI nicht verteufeln. Sie ist ein mächtiges Werkzeug, und richtig eingesetzt kann sie uns wirklich helfen. Die Studien zu KI-Tutoren im Bildungsbereich zeigen vielversprechende Ergebnisse – allerdings nur, wenn die Nutzung gut angeleitet wird und die KI nicht einfach die Antworten liefert, sondern durch Fragen zum eigenen Denken anregt.
Vielleicht ist das die wichtigste Erkenntnis: KI sollte uns zum Denken anregen, nicht davon befreien. Sie sollte uns helfen, bessere Fragen zu stellen, nicht alle Antworten zu liefern. Sie sollte unsere Gedanken schärfen, nicht ersetzen.
Ob mir das gelingt? Ich arbeite daran. Dieser Text hier ist ein Versuch. Ich habe die Struktur selbst entwickelt, die Gedanken selbst gedacht, die Argumente selbst erarbeitet. Die KI hat geholfen, das Ganze zu organisieren und zu formulieren. Aber die Substanz, die Überlegungen, die Zweifel – die kommen von mir.
Und das Unbehagen auch. Denn selbst beim Schreiben dieser Zeilen merke ich: Es ist ein schmaler Grat. Ein ständiges Abwägen. Eine kontinuierliche Entscheidung, wann ich die Hilfe annehme und wann ich sie ablehne. Die Stellschraube richtig einzustellen, ist keine einmalige Aufgabe. Es ist eine tägliche Herausforderung.
Eine Herausforderung, der wir uns stellen müssen. Denn die Alternative – uns einfach treiben zu lassen und die KI entscheiden zu lassen – bedeutet langfristig, dass wir nicht nur Fähigkeiten verlernen, sondern auch die Fähigkeit zum Lernen selbst. Und das wäre ein zu hoher Preis für ein bisschen Bequemlichkeit.
Blockchain nur ein Hype?
- Details
- Kategorie: Blockchain
Während wir diese Zeilen schreiben, ist die generative KI das beherrschende Technologiethema in den Massenmedien und nicht die Blockchain, obwohl einige Kryptowährungen fast täglich neue Höchststände erreichen, allen voran Bitcoin. Aber seit Jahren hat keine Innovation aus der Informatik so viel öffentliche Aufmerksamkeit erhalten wie die KI. Natürlich hat die generative KI in den letzten Jahren grosse Fortschritte gemacht und jeder kann sich selbst davon überzeugen, indem er Bilder, Texte, Musik oder Design generiert. In diesem Beitrag geht es vor allem um das vergangene Hype-Thema Blockchain.
Um das Jahr 2017 herum war Blockchain wahrscheinlich die Lieblingstechnologie einiger neuer CTOs. Allzu oft entscheiden Unternehmen, Behörden oder die Politik nicht danach, was sich langfristig für die Nutzer oder die Gesellschaft auszahlt. Stattdessen basieren ihre Produktstrategien auf Technologien, die gerade hip sind, von den Medien gepusht werden oder von denen das Management überzeugt ist, dass sie sich als das „next big thing“ erweisen werden. Experten bezeichnen dies auch als Technology-driven Design (TDD). Vermutlich aus Mangel an technischem Verständnis bewegen sich Politiker und Manager viel häufiger in diesem TDD-Raum als Entwicklungsabteilungen.
Beispiele von gescheiterten IT-Technologien
Wer seit mehr als drei Jahrzehnten als Softwareentwickler tätig ist, hat schon viele kurzlebige Technologien und deren Misserfolge miterlebt. Einige davon wurden von der breiten Öffentlichkeit gar nicht wahrgenommen. Andere sind teilweise im Bewusstsein vieler Menschen verankert:
- 1990er Jahre VR (Virtuelle Realität): Virtuelle Realität wurde in den 1990er Jahren als der nächste grosse Trend angekündigt, mit Anwendungen von Spielen bis hin zur Bildung. Die Hardware war teuer, die Grafik schlecht und es gab nur wenige praktische Anwendungen. Erst mit modernen Technologien wie der Oculus Rift erlebte VR ein Revival. Es ist aber immer noch ein Insiderprodukt.
- Mitte der 2000er Jahre - Second Life: Damals wurde die virtuelle Welt "Second Life" als nächste Evolutionsstufe des Internets gefeiert, in der Menschen in einer 3D-Umgebung interagieren können. Die Plattform hatte zwar eine Nischen-Community, konnte aber nie den Massenmarkt erreichen. Der technische Aufwand und die fehlende Integration in den Alltag schreckten viele Nutzer ab.
- 2013 - Google Glass: Die Datenbrille von Google wurde als Zukunftstechnologie angepriesen, die Augmented Reality in den Alltag bringen sollte. Datenschutzbedenken, der hohe Preis und der fehlende praktische Nutzen führten dazu, dass das Produkt wenig Anklang fand. Google stellte den Vertrieb der ersten Version ein.
Noch zwei Beispiele aus der Softwareentwicklung:
- Mitte 2000er Jahre: Adobe Flash war ein Ärgernis mit vielen Sicherheitslücken. Mitte der 2000er Jahre sollte Microsoft Silverlight die Alternative werden. Doch mit dem Aufkommen von HTML5 und dem offenen Webstandard sind glücklicherweise sowohl Silverlight als auch Adobe Flash überflüssig geworden.
- Anfang der 2000er Jahre: SOAP (Simple Object Access Protocol) war Anfang der 2000er Jahre ein Standard für den Nachrichtenaustausch in Web Services und galt als unverzichtbar für verteilte Systeme. SOAP ist schwerfällig und komplex, was zu seinem Niedergang führte, als REST und JSON populär wurden, die einfacher und besser für moderne Webanwendungen geeignet sind. SOAP wird nur noch selten in Unternehmensumgebungen eingesetzt, hat aber ausserhalb dieses Bereichs stark an Bedeutung verloren.
Der Gartner Hype-Zyklus
Der Gartner Hype-Zyklus ist ein Modell, das die Entwicklung und Akzeptanz von neuen Technologien und Anwendungen beschreibt. Er wurde von Gartner Inc., einem IT-Marktforschungsunternehmen, entwickelt und wird seit 1995 veröffentlicht. Er besteht aus fünf Phasen, die den Lebenszyklus einer Technologie abbilden.
- Technologischer Auslöser (Technology Trigger): Eine potenzielle technologische Innovation löst einen Hype aus. Es gibt erste Erfolgsgeschichten und Medieninteresse, aber noch keine brauchbaren Produkte oder kommerzielle Machbarkeit.
- Gipfel der überzogenen Erwartungen (Peak of Inflated Expectations): Der Hype erreicht seinen Höhepunkt, wenn viele Erfolgsgeschichten, aber auch viele Misserfolge berichtet werden. Einige Unternehmen investieren in die Technologie, viele nicht.
- Tal der Enttäuschungen (Trough of Disillusionment): Das Interesse nimmt ab, wenn Experimente und Implementierungen nicht die erwarteten Ergebnisse liefern. Viele Anbieter der Technologie scheitern oder geben auf. Nur diejenigen, die ihre Produkte verbessern können, überleben.
- Pfad der Erleuchtung (Slope of Enlightenment): Es werden immer mehr Beispiele für den Nutzen der Technologie für das Unternehmen sichtbar und verständlich. Die Produkte werden weiterentwickelt und verfeinert. Mehr Unternehmen starten Pilotprojekte, konservative Unternehmen bleiben vorsichtig.
- Plateau der Produktivität (Plateau of Productivity): Die Technologie wird zum Mainstream und erreicht eine breite Akzeptanz und Anwendung. Die Kriterien für die Bewertung der Anbieter sind klarer definiert. Der Nutzen der Technologie ist offensichtlich.
Einige der oben genannten Technologien wie Google Glass oder auch Second Life haben diesen Hype-Zyklus ebenfalls durchlaufen. Sie haben es aber nie geschafft, das Plateau der Produktivität zu erreichen.
Hype Cycle 2016
Während ich diesen Beitrag schreibe, gehen wir 8 Jahre zurück und schauen uns den damaligen Hype Cyle an.
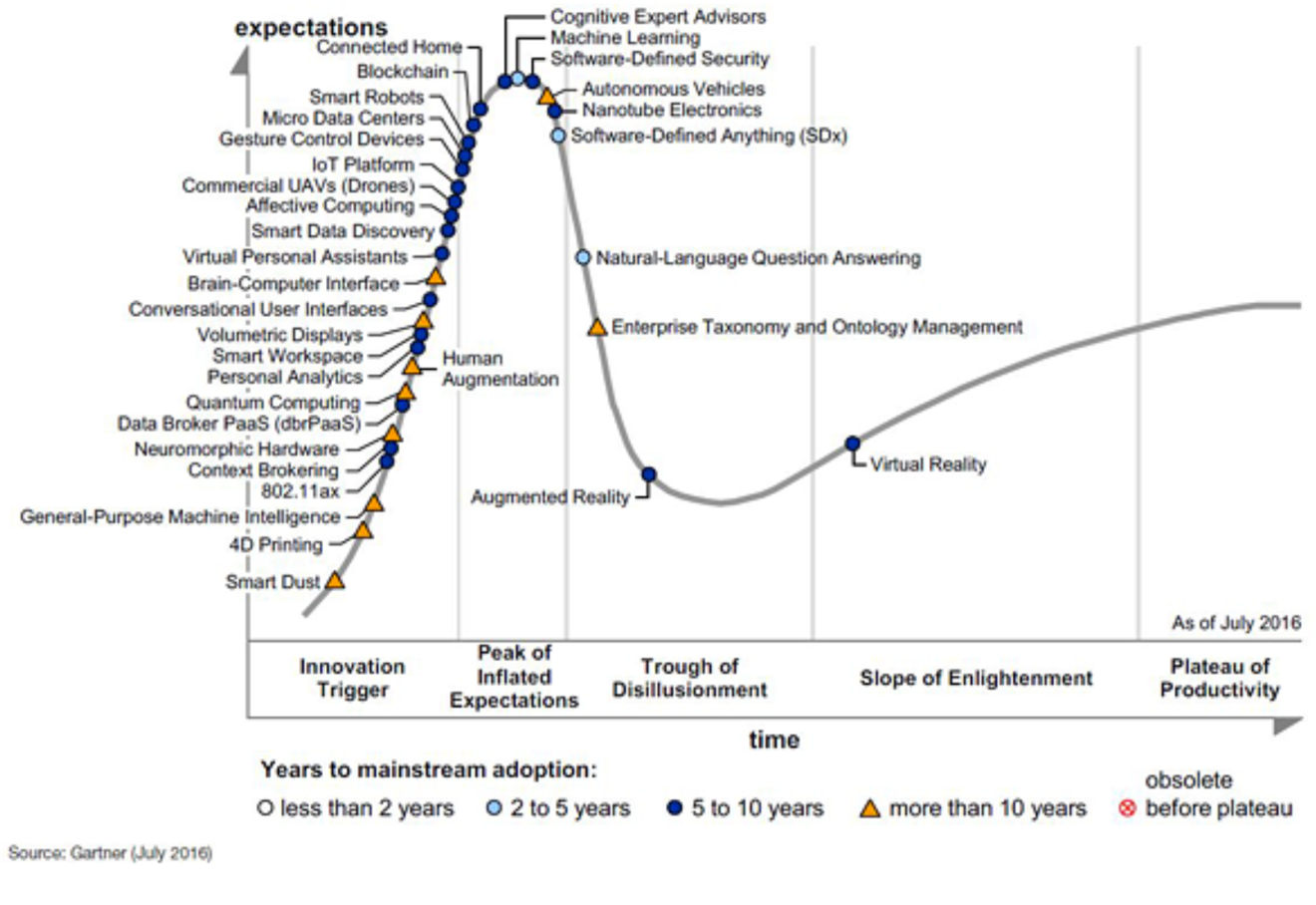
Die drei folgenden Technologien wurden einst als vielversprechende Innovationen gefeiert, haben aber die damaligen Erwartungen bisher nicht erfüllt. Einige stossen auf technologische Hürden, andere haben nur Nischenmärkte erobert, und einigen fehlt noch die breite Akzeptanz. Wahrscheinlich können nur wenige Leser spontan die Ideen hinter diesen Technologien erklären.
- 4D Printing bezeichnet die Herstellung von Materialien oder Objekten, die sich nach dem Druck durch äussere Einflüsse wie Wärme, Feuchtigkeit oder Licht dynamisch verändern können. Es wurde als Weiterentwicklung des 3D-Drucks gefeiert, mit potenziellen Anwendungen in der Medizin, Robotik und Architektur, z. B. für selbstheilende Materialien oder adaptive Strukturen. Trotz einiger Fortschritte in Forschung und Prototypen blieb der breite Durchbruch aus, da die Technologie teuer ist, die Materialvielfalt begrenzt bleibt und konkrete Anwendungen selten sind. Aktuell findet 4D Printing vor allem in spezialisierten Nischen wie der Materialforschung und Prototypenentwicklung Verwendung. Insgesamt gilt es als noch nicht gescheitert, aber deutlich hinter den ursprünglichen Erwartungen zurückgeblieben.
- Nanotube Electronics beschreibt den Einsatz von Kohlenstoff-Nanoröhren (CNTs) in elektronischen Bauteilen, um kleinere, leistungsstärkere und effizientere Geräte zu entwickeln. Obwohl CNTs aufgrund ihrer hervorragenden Eigenschaften als mögliche Nachfolger von Silizium gelten, haben hohe Produktionskosten und technische Hürden ihren breiten Erfolg bislang verhindert. Fortschritte wie CNT-basierte Transistoren und flexible Elektronik zeigen Potenzial, doch die Technologie bleibt bisher auf Nischenanwendungen wie Sensoren, Batterien und leichte Verbundmaterialien beschränkt. In der klassischen Elektronik hat sie den Durchbruch noch nicht geschafft, weshalb sie derzeit als verzögert, aber nicht gescheitert gilt. Langfristig könnte sie erfolgreich werden, wenn Skalierungsprobleme gelöst und Kosten reduziert werden.
- Augmented Reality (AR) bezeichnet die Überlagerung der realen Welt mit digitalen Inhalten wie Bildern, Texten oder Animationen, oft über Smartphones, Tablets oder AR-Brillen. AR wurde mit grossen Erwartungen verbunden, insbesondere für Anwendungen in Gaming, Bildung, Industrie und Einzelhandel, z. B. Pokémon Go, IKEA Place oder Schulungssoftware. Während AR in Nischen wie Navigation, Wartung und Design erfolgreich eingesetzt wird, blieb der grosse Durchbruch im Alltag aus, vor allem wegen hoher Hardwarekosten und begrenzter Inhalte. Fortschritte bei AR-Brillen wie der Apple Vision Pro zeigen Potenzial, aber der Massenmarkt wird erst langsam erschlossen. Insgesamt ist AR nicht gescheitert, sondern entwickelt sich stetig weiter, mit Erfolg in spezialisierten Bereichen und Zukunftsperspektiven für breitere Anwendungen.
Technologien scheitern oft, weil sie nicht den richtigen Zeitpunkt, die richtige Zielgruppe oder einen klaren Mehrwert finden. Häufig überschätzt der Markt ihre Fähigkeiten und unterschätzt gleichzeitig die Herausforderungen bei der Umsetzung. Der Hype Cycle hilft, solche Fälle besser zu verstehen und realistischer einzuschätzen, welche Technologien tatsächlich das Plateau der Produktivität erreichen können. Wie heisst es so schön: Wir neigen dazu, die Auswirkungen einer Technologie kurzfristig zu überschätzen und langfristig zu unterschätzen.
Blockchain und Kryptos
Wenn man Blockchain googelt, erkennt man sofort die starke Verbindung zu Kryptowährungen bzw. Bitcoin. Die Sinnhaftigkeit von Kryptowährungen soll hier nicht diskutiert werden. Dennoch stellt sich natürlich die Frage, welchen Einfluss die Kursschwankungen von Bitcoin auf wirtschaftliche Entscheidungsträger haben, Blockchain als Technologie in ihren Projekten einzusetzen. Laut Google Trends begann das Interesse an der Blockchain im Jahr 2017. Dies war in der Tat der Höhepunkt des Hypes um die Blockchain-Technologie, sowohl aufgrund des Krypto-Booms als auch aufgrund der massiven Aufmerksamkeit, die ICOs und andere Blockchain-Projekte erhielten. Ich vermute, dass die hohen Suchanfragen auf Google nach "Blockchain" ab 2021 vor allem auf Investoren zurückzuführen sind. Diese wollten mehr über die Funktionsweise von Kryptowährungen erfahren, um Investitionen zu tätigen.
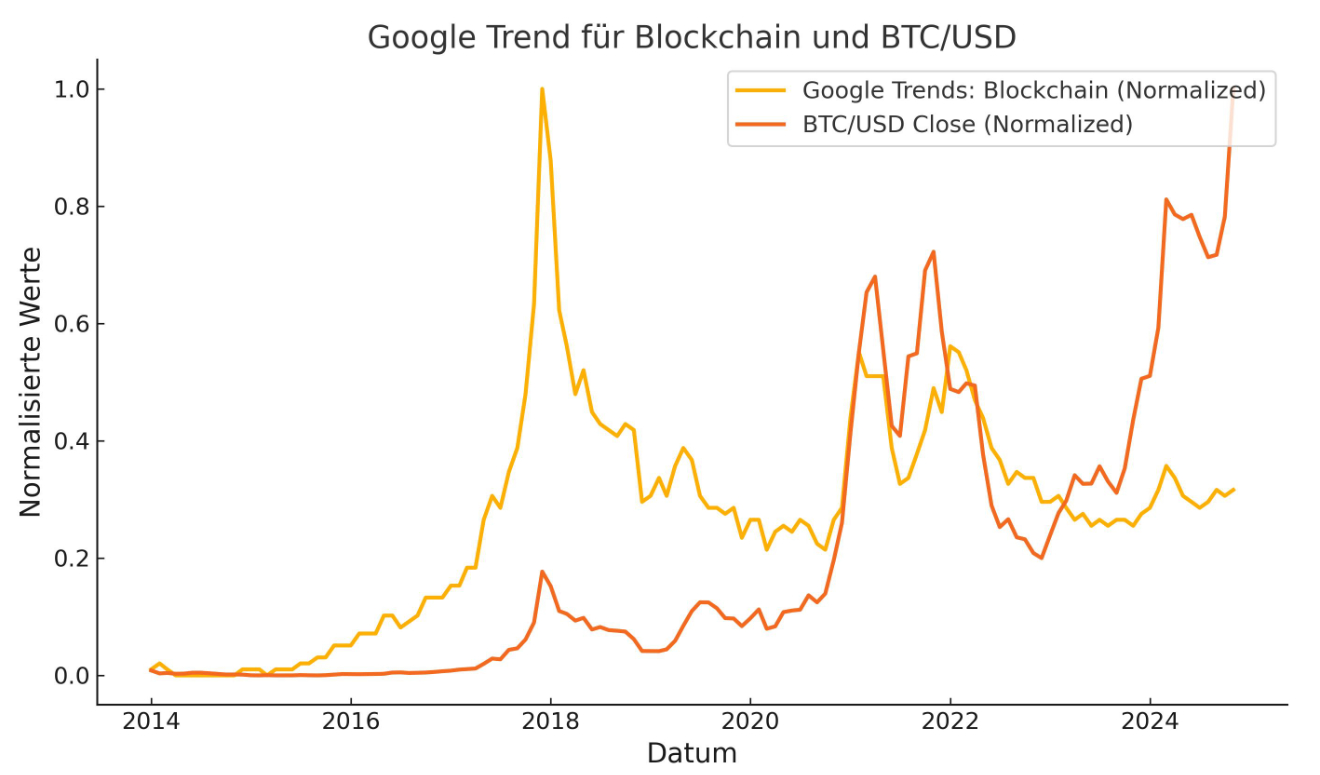
Bereits im Jahr 2019 wurde ein Grossteil der Blockchain-Projekte zurückgefahren, was wahrscheinlich auch auf den Kursverfall des Bitcoins zurückzuführen ist. Ab 2022 dürften auch die letzten Entscheidungsträger erkannt haben, dass die Blockchain-Technologie ein Hype war. Andererseits ist die Technologie in den letzten Jahren immer ausgereifter geworden.
Es ist natürlich fatal, wenn Blockchain in Projekten eingesetzt wird, obwohl es bessere Alternativen gibt. Die Blockchain-Technologie ist eine spezielle Form der Distributed-Ledger-Technologie (DLT), die auf der Verkettung von Datenblöcken basiert. Natürlich sind Kryptowährungen nur einer von vielen Anwendungsfällen dieser Technologie.
Distributed Ledger Technology (DLT)
Die Nutzungsmöglichkeiten von DTL ist vielfältig und reichen von Smart Contracts aller Art über Kryptowährungen und den Datenaustausch bis zur Überwachung von Lieferketten. Die Zahl der Unternehmen, die DLT einsetzen, nimmt zu; im letzten Jahr waren es noch weniger als drei Prozent. Dennoch steckt die Technologie noch in einem frühen Entwicklungsstadium. Knapp die Hälfte der Befragten plant in absehbarer Zeit keine Projekte dazu.
Distributed Ledger Technology (DLT) und Blockchain werden oft synonym verwendet, unterscheiden sich jedoch grundlegend. DLT ist der Oberbegriff für Technologien, die digitale Register in einem dezentralen Netzwerk synchronisieren und verwalten, ohne dass eine zentrale Instanz erforderlich ist. Blockchain hingegen ist eine spezifische Form von DLT, bei der Daten in Blöcken gespeichert und kryptografisch miteinander verknüpft werden. Während Blockchain eine lineare, unveränderliche Struktur hat, kann DLT flexibel gestaltet sein, etwa in Form von Directed Acyclic Graphs (DAG). DLT bietet grössere Skalierbarkeit und Anpassungsfähigkeit, da es nicht auf die blockbasierte Organisation beschränkt ist. Blockchain überzeugt dagegen mit hoher Sicherheit und Transparenz, ist jedoch oft ressourcenintensiver und weniger effizient. DLT wird häufig in geschlossenen, permissioned Netzwerken verwendet, während Blockchains wie Bitcoin oder Ethereum in öffentlichen, permissionless Netzwerken arbeiten. Die Wahl zwischen DLT und Blockchain hängt stark vom Anwendungsfall ab: Blockchain eignet sich besonders für Anwendungen, die maximale Transparenz und Unveränderlichkeit erfordern, während DLT eine breitere Palette an Szenarien abdeckt, etwa in der Finanzindustrie oder im Supply-Chain-Management. Kurz gesagt: Jede Blockchain ist eine DLT, aber nicht jede DLT ist eine Blockchain.
Blockchain vs DLT
Blockchain-Projekte scheitern oft an hohen Kosten, begrenzter Skalierbarkeit, rechtlichen Hürden und fehlendem Mehrwert gegenüber bestehenden Lösungen. Insbesondere im Bereich Datenschutz und Compliance stossen viele öffentliche Blockchains an ihre Grenzen, da Daten nur schwer gelöscht oder verändert werden können. Zudem erfordern viele Anwendungsfälle eine höhere Performance und einen geringeren Energieverbrauch, was Blockchains mit traditionellen Konsensmechanismen nicht bieten können. DLT wird daher zunehmend bevorzugt, da es flexibler ist und besser an spezifische Anforderungen angepasst werden kann. Geschlossene, autorisierte Netzwerke bieten Vorteile wie höhere Effizienz, Datenschutz und einfachere Integration in bestehende Systeme. DLT ermöglicht auch eine kostengünstigere Implementierung und ist oft besser geeignet, regulatorische Anforderungen zu erfüllen. Während Blockchain für Anwendungen wie Kryptowährungen und Smart Contracts relevant bleibt, erfüllen DLT-Lösungen die Bedürfnisse vieler Unternehmen und Branchen besser.
Insgesamt zeigt sich, dass Blockchain nicht immer die optimale Lösung ist, während DLT eine breitere und praktikablere Alternative darstellt.
Gescheiterte Blockchain-Projekte
Grundsätzlich scheitern weit mehr als die Hälfte aller IT-Projekte. Dies geschieht jedoch meist in der Initialisierungsphase, in der das Scheitern noch günstig ist. Bei Blockchain-Projekten ist die Misserfolgsquote noch höher. Die Gründe für das Scheitern eines Projekts sind vielfältig, wie die beiden folgenden Projekte zeigen. Nicht selten scheitert ein Projekt auch an mangelnder Nutzerakzeptanz.
- Schulzeugnisse in Sachsen-Anhalt: Dieses Blockchain-Projekt für digitale Schulzeugnisse scheiterte aufgrund schwerwiegender Sicherheitslücken. Ziel des Projekts war es, Schulzeugnisse fälschungssicher und digital über Blockchain bereitzustellen, doch IT-Experten konnten das System manipulieren und gefälschte Zeugnisse erstellen. Diese Schwachstellen führten dazu, dass das Pilotprojekt im Jahr 2022 eingestellt wurde. Kritiker bemängelten zudem, dass die Blockchain-Technologie für diesen Anwendungsfall überdimensioniert und unnötig kompliziert war. Stattdessen könnten einfachere und sicherere Lösungen effizienter eingesetzt werden. Das Scheitern verdeutlicht die Herausforderungen bei der praktischen Umsetzung von Blockchain in Verwaltungsprozessen.
- TradeLens-Plattform: Diese Plattform, ein Gemeinschaftsprojekt von Maersk und IBM, sollte die globale Lieferkette mit Hilfe der Blockchain-Technologie revolutionieren. Ziel war es, die Transparenz und Effizienz im internationalen Handel zu erhöhen, indem Dokumente und Transaktionen dezentral und fälschungssicher verwaltet werden. Trotz der technischen Funktionalität scheiterte das Projekt daran, genügend Teilnehmer aus der Industrie zu gewinnen, da viele Unternehmen Bedenken hinsichtlich Datenfreigabe und Wettbewerbsneutralität hatten. Die mangelnde Akzeptanz führte dazu, dass TradeLens 2023 eingestellt wurde. Dieses Scheitern zeigt, dass die Blockchain-Technologie allein nicht ausreicht, um komplexe, globale Systeme zu transformieren - die Zusammenarbeit und das Vertrauen aller Beteiligten sind ebenso entscheidend.
Von der Blockchain zu KI
In den letzten Jahren hat sich der Fokus vieler Entwickler und Unternehmen von Blockchain auf künstliche Intelligenz (KI) verlagert. Während die Blockchain einst als revolutionäre Technologie galt, um zentrale Instanzen zu ersetzen und Transparenz zu fördern, hat sie die hohen Erwartungen oft nicht erfüllt. Viele Blockchain-Projekte sind an Skalierungsproblemen, hohen Kosten und mangelnder Praxisrelevanz gescheitert. KI hingegen hat in kürzester Zeit beeindruckende Fortschritte gemacht und wird in nahezu allen Branchen - von der Automatisierung über das Gesundheitswesen bis hin zum Kundenservice - breit eingesetzt. Ein wesentlicher Grund für den Boom von KI ist der unmittelbare wirtschaftliche Nutzen: Unternehmen können mit KI Prozesse optimieren, Kosten senken und datenbasierte Entscheidungen treffen. Darüber hinaus sind KI-Werkzeuge wie maschinelles Lernen und generative Modelle durch Frameworks wie TensorFlow und PyTorch leichter zugänglich geworden. Auch die Investitionen in KI sind enorm gestiegen, während die Blockchain nach dem Hype um Kryptowährungen und NFTs an Aufmerksamkeit verloren hat. Ein weiterer Faktor ist die breite Skalierbarkeit von KI-Lösungen, die sowohl für Start-ups als auch für grosse Unternehmen attraktiv sind. Im Gegensatz dazu bleibt die Blockchain oft auf Nischenanwendungen. Die Geschwindigkeit, mit der KI sichtbare Ergebnisse liefert, macht sie für Unternehmen attraktiver als Blockchain, die oft lange Implementierungszeiten erfordert.
Trotzdem bleibt Blockchain in einigen Bereichen relevant, insbesondere in Kombination mit KI, zum Beispiel für die sichere und transparente Verifizierung von Trainingsdaten. Insgesamt zeigt die Hinwendung zu KI, dass Unternehmen und Entwickler heute Technologien den Vorzug geben, die konkrete und unmittelbare Vorteile bieten. KI verkörpert genau das - eine sich entwickelnde Technologie, die sich zunehmend im Alltag bewährt und die Zukunft vieler Branchen prägen kann. Obwohl sie noch nicht vollständig ausgereift ist, fasziniert sie sowohl die Menschen, die sie anwenden, als auch die Unternehmen, die sie zunehmend nutzen können.
Fazit
Glücklicherweise haben die meisten Entscheidungsträger erkannt, dass Blockchain oft eine schlechte Wahl für ihren Anwendungsfall wäre. Die Datenstruktur einer Blockchain ist im Vergleich zu relationalen Datenbanken sehr einschränkend, da sie keine Flexibilität für Änderungen, komplexe Beziehungen oder grosse Datenmengen bietet. Während Blockchains für spezifische Anwendungsfälle wie Unveränderbarkeit, Transparenz und Dezentralisierung sinnvoll sind, bleiben relationale Datenbanken für die meisten Geschäftsanwendungen die bessere Wahl. Blockchains sollten daher nur dort eingesetzt werden, wo ihre Einschränkungen durch spezifische Vorteile gerechtfertigt sind. Ich könnte die negativen Eigenschaften einer Blockchain beliebig fortsetzen, insbesondere der hohe Energieverbrauch, die begrenzte Skalierbarkeit, die Komplexität und die Kosten machen Blockchain oft unpraktisch für viele Anwendungsfälle. Sie sollte daher nur in Szenarien eingesetzt werden, in denen ihre einzigartigen Eigenschaften unverzichtbar sind - ansonsten bleiben konventionelle Technologien die bevorzugte Wahl.
Medialer Hype um digitale Evolution
- Details
- Kategorie: Maschinelles Lernen
Die Zeitungen und Magazine der letzten 18 Monate sind überzogen von populärwissenschaftlichen Texten zu den Themen maschinelles Lernen, Big Data, Roboter, Supercomputer usw., dabei werden oftmals unnötige Ängste geschürt. Beispielhaft ist die Zunahme des Suchbegriffes "Internet of Things" bei Google:
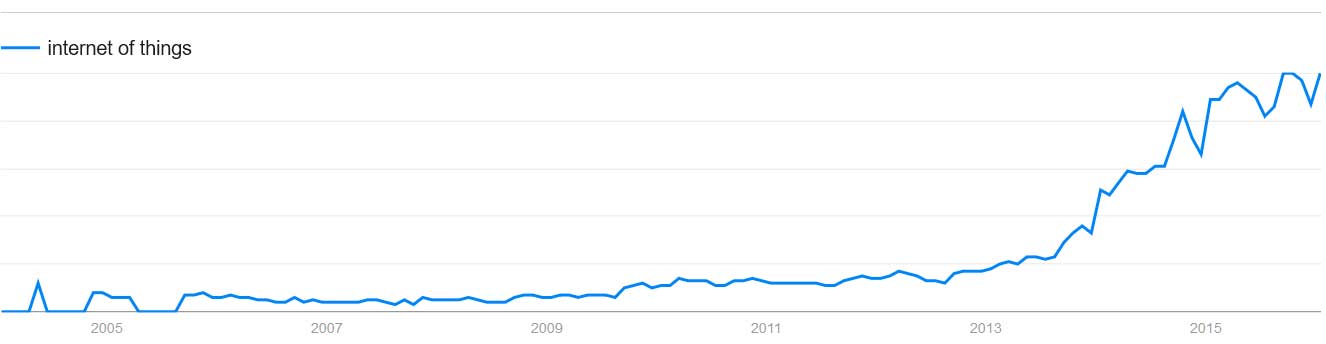
Quelle: Google Trends
Besonders die Überhöhung der künstlichen Intelligenz (KI) als quasi übermenschliches Wesen führt bei den Menschen zu ökonomischen Existenzängsten. Übrigens benutze ich den Begriff KI ungern. Grundsätzlich halte ich den Computer für dumm, der glücklicherweise nach wie vor nach programmierten Algorithmen funktioniert.
Überhöhte populärwissenschaftliche Texte
Mich erinnert diese mediale Präsenz der "digitalen Evolution" an die Dotcom-Blase um die Jahrtausendwende. Auch damals schätzte die Berichterstattung den Zeithorizont des Fortschrittes falsch ein. Die angekündigten technologischen Errungenschaften konnten sich später mehrheitlich etablieren, jedoch benötigte dies rund ein Jahrzehnt und nicht nur 2 bis 3 Jahre. Bei jetzigem Hype werden zusätzlich die Potenziale einiger Technologien völlig überspitzt dargestellt.
Exemplarisch erwähne ich folgenden Artikel von Marco Metzler, NZZ vom 3.01.2016: "Uns braucht es bald nur noch als Konsumenten". In diesem Beitrag hat es einige oberflächliche Aussagen über die Fähigkeiten der KI:
- Google Translate wurde mit vielsprachigen Texten gefüttert und hat sich Übersetzen selbst beigebracht. Für das Verständnis der meisten Texte reicht das völlig. Übersetzer erhalten nur noch die anspruchsvollen Aufträge.
- Früher ersetzten Maschinen Muskelkraft, heute geistige Fähigkeiten. Neuerdings beherrschen Computer nicht mehr nur repetitive, einfache Tätigkeiten, sondern immer komplexere. Sie erkennen Muster besser als Menschen.
Ich weiss nicht, ob der Herr Metzler wenig Realitätsbezug zur Informatik hat oder ob er einfach im Medienhype mitschreibt. Wie gut bzw. schlecht Google Translate übersetzt, können Sie selbst nachprüfen. Schon bei der Übersetzung von einfachen Texten braucht es oftmals eine anstrengende kreative Improvisation, um darin eine Information zu erkennen. Es ist eine unbedachte Aussage, dass der Computer den Menschen bei der Mustererkennung übertrifft. Scheinbar hat Marco Metzler wenig Ahnung, für was der Begriff Mustererkennung alles steht.
Hardware und Software gleich digitaler Fortschritt
Oft wird in den Medien die Gesetzmässigkeit der verdoppelten Leistung der Computer zitiert. Vor circa 50 Jahren veröffentlichte Gordon Moore einen Aufsatz mit der Aussage der jährlichen Verdoppelung der Rechenleistung. Später korrigierte er diese Annahme und sprach von einer Verdoppelung alle zwei Jahre. Daraus leiten gewisse Medien und Buchautoren ein grundsätzlich exponentielles Wachstum des digitalen Fortschritts ab. Dabei scheinen sie zu vergessen, dass die Software von Menschen geschrieben wird und dieser sein Potenzial nur geringfügig steigern kann. Das Wort "Exponentiell" sollte bedacht eingesetzt werden, andernfalls verführt dies zu fragwürdigen Aussagen. Im Folgenden spricht der WEF-Gründer Klaus Schwab von exponentiellen Veränderung der Wettbewerbsverhältnisse; was immer er damit meint:
Quelle: SRF, WEF - «Da kommt ein Tsunami auf uns zu»
Sicherlich beflügeln schnellere Rechner das maschinelle Lernen, was die Bewältigung von komplexeren Aufgaben ermöglicht. Oft bestehen Systeme nebst integrierten Schaltungen auch aus Hardware, die nicht dem exponentiellen Wachstum unterliegt. Trotzdem, erst die zunehmende Miniaturisierung und Leistungssteigerung der integrierten Schaltkreise ermöglicht die heutigen automatisieren Systeme, die auf ihre Umwelt reagieren können.
Quelle: SRF ECO Spezial vom 9.11.2015 - Wenn Roboter Menschen ersetzen
Das überschätzte selbstfahrende Fahrzeug
Die Berichterstattung über selbstfahrende Autos war im letzten Jahr sehr unkritisch. Insbesondere überzogene Erwartung an das Google-Auto. In gewissen Berichterstattungen wird tatsächlich behauptet, dass Roboterautos bereits sicherer sind als herkömmliche PWs. In der Realität wäre ein Google-Auto im indischen Berufsverkehr nach einigen Metern auf der Strasse völlig überfordert. In manchen Ländern organisieren sich die Verkehrsteilnehmer mit Blickkontakt und mehr oder weniger freundlichen Gesten. Die Bewältigung vieler solcher alltäglicher Verkehrssituationen ist technisch ungelöst. Selbstfahrende Fahrzeuge müssen beispielsweise mit den anderen Verkehrsteilnehmern kommunizieren können, sei dies von Fahrzeug zu Fahrzeug oder mit dem Fussgänger. Autonome Autos orientieren sich mit unterschiedlichen Sensoren, bei starkem Regen oder unter Schneeverhältnissen funktioniert ein Teil dieser Systeme nicht mehr oder nur sehr eingeschränkt.
Eine erweiterte Strasseninfrastruktur, die mit den vernetzten autonomen Fahrzeugen kommuniziert, kann möglicherweise die vom Menschen erwartete hohe Sicherheit erbringen. Daher müssten die Regierungen bzw. privaten Strasseneigentümer und die unterschiedlichen Fahrzeughersteller dringend zusammenarbeiten, sonst wird nichts aus diesem Traum. Zudem wird die höchste Sicherheit im Strassenverkehr erst erreicht, wenn alle Fahrzeuge vom Computer gesteuert werden. Dieses gesellschaftliche Problem könnte sich als die grösste Hürde für den Erfolg des autonomen Fahrzeuges erweisen.
Fazit
Die Berichterstattung über die digitale Evolution in den Zeitungen und Magazinen ist momentan oberflächlich und völlig überhöht. Zu oft wird das mooresche Gesetz im Zusammenhang mit dem digitalen Fortschritt verallgemeinert. Dies führt zu einer übertriebenen Erwartungshaltung. Kaum eine andere Technologie jenseits der integrierten Schaltkreise wird über mehrere Jahrzehnte einen solchen exponentiellen Fortschritt erzielen. Trotz Fortschritten beim maschinellen Lernen bewegt sich die Befähigung für die Bewältigung komplexer Probleme sehr langsam.
Die maschinelle Übersetzung der von Menschen geschriebenen Sprache zeigt die Grenzen des maschinellen Lernens. Der Computer bzw. dessen Algorithmus versteht den Inhalt einer Sprache nicht und scheitert öfters an der Mehrdeutigkeit der Wörter. Die Übersetzungsqualität kann sicherlich noch gesteigert werden, jedoch bleiben die letzten paar Prozente zu einer hundertprozentigen korrekten Übersetzung mit der digitalen Technologie aus meiner Sicht unüberwindbar. Dieses nicht Hundertprozentige bzw. der überlegene Mensch werden wir vermehrt beobachten können, wo sich Maschinen an komplexen Problemen versuchen. Zu dieser Kategorie gehört auch das selbstfahrende Auto. Bedauerlicherweise gibt es noch immer Forscher wie Dileep George die das Gehirn mit einer Maschine gleichsetzen und es für reproduzierbar halten.
Quelle: SRF Trend vom 23.01.2016 - WEF 2016: Die 4. industrielle Revolution: Fluch oder Segen?
Dieser Herr hat ein Startup-Unternehmen gegründet, möglicherweise erleichtert diese Aussage in Kalifornien die Investorensuche.
Wahrscheinlich ist die Übertreibung teilweise der aktuell hohen Börsenkapitalisierung einiger US-Technologiefirmen wie Apple, Microsoft, Amazon, Alphabet usw. geschuldet. Die Übertreibungen an den Aktienmärkten untermauern solche überzogene Technologiestorys und beruhigen die Anleger. Allenfalls lässt es sich auch mit schüren von Ängsten um Arbeitsplatzverlust oder dem Wettbewerb Mensch gegen Maschine erklären. Somit kann kostengünstig die Auflage bzw. Klickrate von Büchern, Zeitungen und Onlinemedien erhöht werden.
Seite 1 von 2